Presentation
Introduction
Multicast is the process of sending every single packet to multiple destinations. Motivations behind multicast facilities are to handle one-to-many communications in a wide-area network with the lowest network and end-system overheads. In contrast to best-effort multicast, that typically tolerates some data losses and is more suited for real-time audio or video for instance, reliable multicast requires that all packets are safely delivered to the destinations. Desirable features of reliable multicast include, in addition to reliability, low end-to-end delays, high throughput and scalability.These characteristics fit perfectly the need of the grid computing and distributed computing communities as communications in a computing grid make an intensive usage of data distribution and collective operations (submissions of jobs to computing farms, program and data distribution between computing resources, gather and synchronization barrier operations\ldots). In the past few years, many software that propose grid environments for gaining access to very large distributed computing resources have been made available (e.g. Condor, Globus, Legion, Netsolve to name a few). They all implicitly rely on an efficient underlying data distribution mechanism. In the example of a very simple grid session, an initiator typically sends data and control programs to a pool of computing resources; waits for some results, iterates this process several time and eventually ends the session. Therefore an efficient multicast mechanism dramatically reduce the end-to-end latency for running applications on an Internet-based grid (especially for fine-grained applications) and to minimize the overhead at the source (the source itself may need to gather results and build data for the next computing step). More complex grid sessions put higher demands on the network resources and on the multicast/broadcast communication facilities (cooperation among the receivers, receivers acting as sources for the other receivers,...)
Reliable multicast difficulties
Meeting the objectives of reliable multicast is not an easy task. In the past, there have been a number of propositions for reliable multicast protocols that rely on complex exchanges of feedback messages (ACK or NACK):XTP, SRM, RMTP, TMTP. These multicast protocols usually take the end-to-end solution to perform loss recoveries. Most of them fall into one of the following classes: sender-initiated, receiver-initiated and receiver-initiated with local recovery protocols. In sender-initiated protocols, the sender is responsible for both the loss detection and the recovery (i.e. XTP). These protocols do not scale well to a large number of receivers due to the ACK implosion problem in the source. Receiver-initiated protocols move the loss detection responsibility to the receivers. They use NACKs instead of ACKs. However they still suffer from the NACK implosion problem when a large number of receivers have subscribed to the multicast session. In receiver-initiated protocols with local recovery, the retransmission of a lost packet can be performed by any receiver (SRM) in the neighborhood or by a designated receiver in a hierarchical structure (RMTP). All of the above schemes do not provide exact solutions to all the loss recovery problems. This is mainly due to the lack of topology information at the end hosts.Active Reliable Multicast, the DyRAM approach
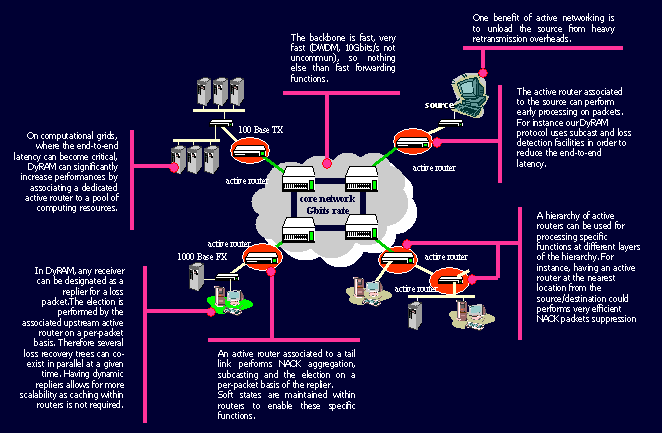
In active networking, routers themselves play an active role by executing application-dependent services on incoming packets. Recently, the use of active network concepts where routers themselves could contribute to enhance the network services by customized functionalities have been proposed in the multicast research community and can be very beneficial to the grid community. Contributing mainly on feedback implosion problems, retransmission scoping and cache of data, these active reliable multicast protocols open new perspectives for achieving high throughput and low latency on wide-area networks:In this project, we investigate the benefits a computing grid can draw from an underlying active reliable multicast service. We propose the Dynamic Replier Active Reliable Multicast protocol for reducing the end-to-end latency.
- the cache of data packets allows for local recoveries of loss packets and reduces the recovery latency.
- the global or the local suppression of NACKs reduces the NACK implosion problem.
- the subcast (partial multicast) of repair packets to a set of receivers limits both the retransmission scope and the bandwidth usage.
A typical grid would have computing resources distributed across an Internet-based network with a high-speed backbone network in the core (typically the one provided by the telecommunication companies) and several lower-speed (up to 1Gbits/s), with respect to the throughput range found in the backbone, access networks at the edge.
People
Cong-Duc Pham , assistant professor.Moufida Maimour , PhD student.Faycal Bouhafs , senior developement engineer.Publications
- M. Maimour, C. Pham, "Towards an Application-aware Multicast Communication Framework for Computational Grids", To appear in Proceedings of the 7th Asian Computing Science Conference, Hanoi, Vietnam, December 4-6, 2002.
- M. Maimour, C. Pham, "An Active Reliable Multicast Framework for the Grids", Proceedings of the International Conference on Computational Science (ICCS 2002), LNCS 2329&2330&2331, April 21-24 2002, Amsterdam, The Nederlands, pp588-597.Slides .ppt.gz
- M. Maimour, C. Pham, "Active Reliable Multicast for Efficient Data Distribution on an Internet-based Grid Computing Infrastructure", Proceedings of the International Conference on Internet Computing (IC'2001), June 25-28, 2001, Las Vegas, USA, pp437-443. Slides .ppt.gz
Related publications
- M. Maimour, J. Mazuy, C. Pham, "The Cost of Active Services in Active Reliable Multicast", Proceedings of IEEE 4th Annual International Workshop on Active Middleware Services (AMS 2002), July 24-26, 2002, Edinburg, UK, pp67-72.Slides .ppt.gz
- M. Maimour, C. Pham, "Dynamic Replier Active Reliable Multicast (DyRAM)", Proceedings of 7th IEEE Symposium on Computers and Communications (ISCC 2002), July 1-4 2002, Taormina, Italy.
- M. Maimour, C. Pham, "A Loss Detection Service for Active Reliable Multicast Protocols", Proceedings of the International Network Conference (INC'2002), July 15-18 2002, Plymouth, UK.
- L. Lefèvre, C. Pham, P. Primet, B. Tourancheau, B. Gaidioz, J. P. Gelas, M. Maimour, "Active Networking Support for The Grid", Proceedings of the third International Working Conference on Active Networks (IWAN'01), September 30 and October 1-2 2001, Philadelphia, USA.
- M. Maimour, C. Pham, "A Throughput Analysis of Reliable Multicast Protocols in an Active Networking Environment", Proceedings of the Sixth IEEE Symposium on Computers and Communications (ISCC 2001), 3-5 July, 2001, Hammamet, Tunisia. Slides .ppt.gz
Related presentations and talks
- Active Reliable Multicast: How it works, how it can be used on computational grids. Invited talk at SUN Labs Europe, Grenoble, France. February 14th, 2002.Slides .ppt.gz
- Poster of the DyRAM protocol. A0 format poster .ppt
- Active Reliable Multicast: Challenges for the Next Internet. DEA DIF course, ENS-Lyon, France. December 5th, 2001.Slides ARM_tutorial.ppt.gz and Slides dyram_mm.ppt.gz
- Communication networks, active networking and reliable multicast. Seminar at the LIP laboratory, Lyon, France. June 12th, 2001. Slides .ppt.gz
- Active Networks and Applications. Talk at the MIM2 seminar, Venosc, France. December 6th, 2000. Slides .ppt.gz
Grid related links
The european DataGrid project and its associated links to other grid projects
The Global Grid Forum and its associated links to other grid initiatives
The Grid High-Performance Networking research (GHPN) group of Global Grid Forum
The Globus middleware project and the related research papers and presentationsMulticast related links
General introduction to reliable multicast
Reliable Multicast: from End-to-End Solutions to Active Solutions
General presentation of error recovery mechanisms
Lots of links on reliable multicast
The JRMS library